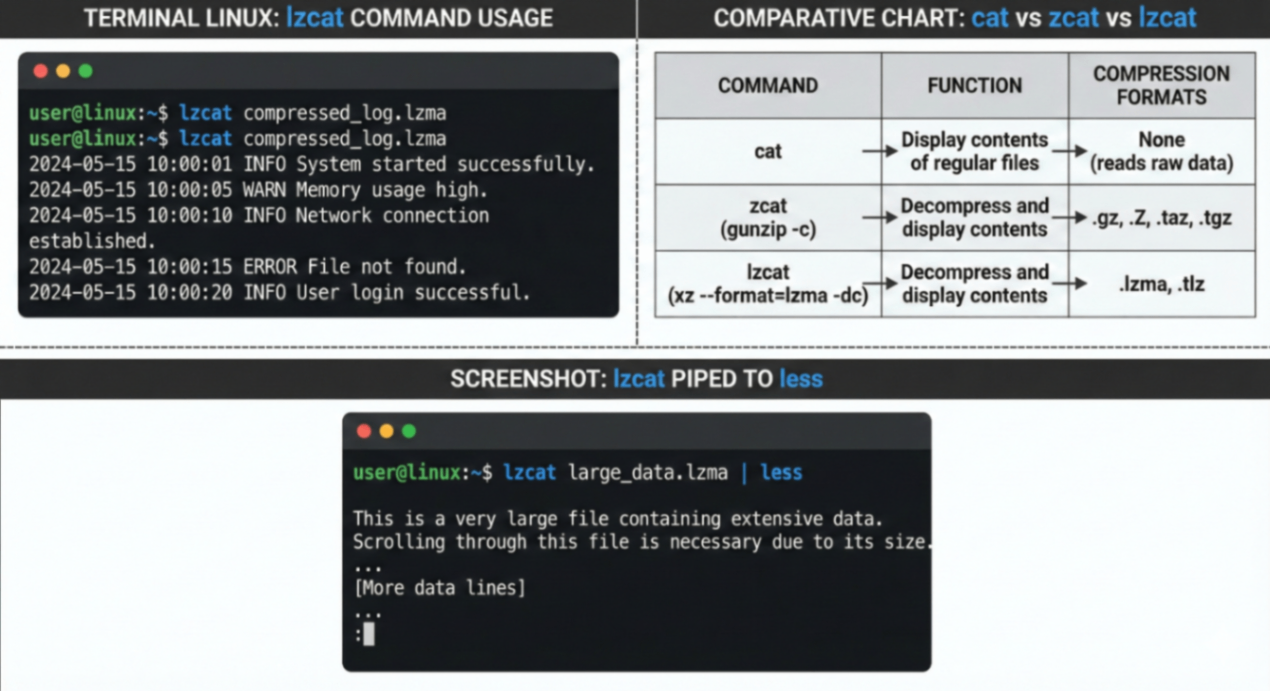
Comando Linux xz, unxz, xzcat, lzma, unlzma, lzcat
xz , unxz , xzcat , lzma , unlzma e lzcat compressa ou descomprimir .xz e .lzma arquivos.
Descrição
O xz é uma ferramenta de compactação de dados de uso geral com sintaxe de linha de comando semelhante ao gzip e bzip2 . O formato de arquivo nativo é o formato .xz , mas o formato .lzma herdado usado pelo LZMA Utils e os fluxos compactados brutos sem cabeçalhos de formato de contêiner também são suportados.
xz compacta ou descomprime cada arquivo de acordo com o modo de operação selecionado. Se nenhum arquivo for fornecido ou o arquivo for especificado como um traço (” – “), xz lê da entrada padrão e grava os dados processados na saída padrão. O xz recusará (exibirá um erro e pulará o arquivo) para gravar dados compactados na saída padrão, se for um terminal . Da mesma forma, o xz se recusará a ler dados compactados da entrada padrão, se for um terminal.
A menos que –stdout seja especificado, arquivos diferentes de ” – ” são gravados em um novo arquivo cujo nome é derivado do nome do arquivo de origem:
- Ao compactar, o sufixo do formato do arquivo de destino ( .xz ou .lzma ) é anexado ao nome do arquivo de origem para obter o nome do arquivo de destino.
- Ao descompactar, o .xz ou .lzma sufixo é removido do nome do arquivo para obter o nome do arquivo de destino. O xz também reconhece os sufixos .txz e .tlz e os substitui pelo sufixo .tar .
Se o arquivo de destino já existir, um erro será exibido e o arquivo será ignorado.
A menos que grave na saída padrão, xz exibe um aviso e pula o arquivo se qualquer um dos seguintes itens se aplicar:
- O arquivo não é um arquivo regular. Links simbólicos não são seguidos e, portanto, não são considerados arquivos regulares.
- O arquivo possui mais de um link físico .
- O arquivo está definido como setuid , setgid ou sticky bit.
- O modo de operação é definida para comprimir o ficheiro e já tem um sufixo do formato de ficheiro de destino ( .xz ou .txz quando se comprime para o .xz formato, e .lzma ou .tlz quando se comprime para o .lzma formato).
- O modo de operação está definido para descompactar e o arquivo não possui um sufixo de nenhum dos formatos de arquivo suportados ( .xz , .txz , .lzma ou .tlz ).
Após compactar ou descompactar o arquivo, xz copia o proprietário, o grupo, as permissões, o tempo de acesso e o tempo de modificação do arquivo de origem para o arquivo de destino. Se a cópia do grupo falhar, as permissões serão modificadas para que o arquivo de destino não se torne acessível aos usuários que não tiveram permissão para acessar o arquivo de origem. O xz ainda não suporta a cópia de outros metadados, como listas de controle de acesso ou atributos estendidos.
Depois que o arquivo de destino é fechado com sucesso, o arquivo de origem é removido, a menos que –keep tenha sido especificado. O arquivo de origem nunca será removido se a saída for gravada na saída padrão.
O envio de sinais SIGINFO ou SIGUSR1 para o processo xz faz com que as informações de progresso sejam impressas com erro padrão. Isso tem uso limitado, já que quando o erro padrão é um terminal, o uso de –verbose exibe um indicador de progresso com atualização automática.
Uso de memória
O uso da memória do xz varia de algumas centenas de kilobytes a vários gigabytes, dependendo das configurações de compactação. As configurações usadas ao compactar um arquivo determinam os requisitos de memória do descompactador. Normalmente, o descompactador precisa de 5% a 20% da quantidade de memória necessária para o compressor ao criar o arquivo. Por exemplo, descompactar um arquivo criado com xz -9 atualmente requer 65 MiB de memória. Ainda assim, é possível ter arquivos .xz que requerem vários gigabytes de memória para descompactar.
Especially users of older systems may find the possibility of very large memory usage annoying. To prevent uncomfortable surprises, xz has a built-in memory usage limiter, which is disabled by default. While some operating systems provide ways to limit the memory usage of processes, relying on it wasn’t deemed to be flexible enough.
The memory usage limiter can be enabled with the command line option –memlimit=limit. Often it is more convenient to enable the limiter by default by setting the environment variable XZ_DEFAULTS, e.g., XZ_DEFAULTS=–memlimit=150MiB. It is possible to set the limits separately for compression and decompression by using –memlimit-compress=limit and –memlimit-decompress=limit. Using these two options outside XZ_DEFAULTS is rarely useful because a single run of xz cannot do both compression and decompression and –memlimit=limit (or -M limit) is shorter to type on the command line.
If the specified memory usage limit is exceeded when decompressing, xz displays an error and decompressing the file will fail. If the limit is exceeded when compressing, xz will try to scale the settings down so that the limit is no longer exceeded (except when using –format=raw or –no-adjust). This way the operation won’t fail unless the limit is very small. The scaling of the settings is done in steps that don’t match the compression level presets, e.g., if the limit is only slightly less than the amount required for xz -9, the settings will be scaled down only a little, not down to xz -8.
Concatenating and padding with .xz files
It is possible to concatenate .xz files as is. xz will decompress such files as if they were a single .xz file.
It is possible to insert padding between the concatenated parts or after the last part. The padding must consist of null bytes and the size of the padding must be a multiple of four bytes. This can be useful e.g., if the .xz file is stored on a medium that measures file sizes in 512-byte blocks.
Concatenation and padding are not allowed with .lzma files or raw streams.
Syntax
xz [option]... [file]...
unxz is equivalent to xz –decompress.
xzcat is equivalent to xz –decompress –stdout.
lzma is equivalent to xz –format=lzma.
unlzma is equivalent to xz –format=lzma –decompress.
lzcat is equivalent to xz –format=lzma –decompress –stdout.
Options: operation modes
These options tell xz what mode to use. If more than one mode is specified, the last one takes effect.
| -z, –compress | Compress. This option is the default operation mode when no operation mode option is specified and no other operation mode is implied from the command name (for example, unxz implies –decompress). |
| -d, –decompress, –uncompress | Decompress. |
| -t, –test | Test the integrity of compressed files. This option is equivalent to –decompress –stdout except that the decompressed data is discarded instead of being written to standard output. No files are created or removed. |
| -l, –list | Print information about compressed files. No uncompressed output is produced, and no files are created or removed. In list mode, the program cannot read the compressed data from standard input or from other unseekable sources. The default listing shows basic information about files, one file per line. To get more detailed information, use also the –verbose option. For even more information, use –verbose twice, but note that this may be slow, because getting all the extra information requires many seeks. The width of verbose output exceeds 80 characters, so piping the output to e.g., “less -S” may be convenient if the terminal isn’t wide enough. The exact output may vary between xz versions and different locales. For machine-readable output, –robot –list should be used. |
Options: operation modifiers
| -k, –keep | Don’t delete the input files. |
| -f, –force | This option has several effects: • If the target file already exists, delete it before compressing or decompressing. • Compress or decompress even if the input is a symbolic link to a regular file, has more than one hard link, or has the setuid, setgid, or sticky bit set. The setuid, setgid, and sticky bits are not copied to the target file. • When used with –decompress –stdout and xz cannot recognize the type of the source file, copy the source file as is to standard output. This allows xzcat –force to be used like cat for files that have not been compressed with xz. Note that in future, xz might support new compressed file formats, which may make xz decompress more types of files instead of copying them as is to standard output. –format=format can be used to restrict xz to decompress only a single file format. |
| -c, –stdout, –to-stdout | Write the compressed or decompressed data to standard output instead of a file. This implies –keep. |
| –single-stream | Decompress only the first .xz stream, and silently ignore possible remaining input data following the stream. Normally such trailing garbage makes xz display an error. xz never decompresses more than one stream from .lzma files or raw streams, but this option still makes xz ignore the possible trailing data after the .lzma file or raw stream. This option has no effect if the operation mode is not –decompress or –test. |
| –no-sparse | Disable creation of sparse files. By default, if decompressing into a regular file, xz tries to make the file sparse if the decompressed data contains long sequences of binary zeros. It also works when writing to standard output as long as standard output is connected to a regular file and certain additional conditions are met to make it safe. Creating sparse files may save disk space and speed up the decompression by reducing the amount of disk I/O. |
| -S .suf, –suffix=.suf | When compressing, use .suf as the suffix for the target file instead of .xz or .lzma. If not writing to standard output and the source file already has the suffix .suf, a warning is displayed and the file is skipped. When decompressing, recognize files with the suffix .suf in addition to files with the .xz, .txz, .lzma, or .tlz suffix. If the source file has the suffix .suf, the suffix is removed to get the target file name. When compressing or decompressing raw streams (–format=raw), the suffix must always be specified unless writing to standard output, because there is no default suffix for raw streams. |
| –files[=file] | Read the file names to process from file; if file is omitted, file names are read from standard input. File names must be terminated with the newline character. A dash (“–“) is taken as a regular file name; it doesn’t mean standard input. If file names are given also as command line arguments, they are processed before the file names read from file. |
| –files0[=file] | This option is identical to –files[=file] except that each file name must be terminated with the null character. |
Options: basic file format and compression options
| -F format, –format=format | Specify the file format to compress or decompress:
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| -C check, –check=check | Specify the type of the integrity check. The check is calculated from the uncompressed data and stored in the .xz file. This option has an effect only when compressing into the .xz format; the .lzma format doesn’t support integrity checks. The integrity check (if any) is verified when the .xz file is decompressed. Supported check types:
Integrity of the .xz headers is always verified with CRC32. It is not possible to change or disable it. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| -0 … -9 | Select a compression preset level. The default is -6. If multiple preset levels are specified, the last one takes effect. If a custom filter chain was already specified, setting a compression preset level clears the custom filter chain. The differences between the presets are more significant than with gzip and bzip2. The selected compression settings determine the memory requirements of the decompressor, thus using a too high preset level might make it painful to decompress the file on an old system with little RAM. Specifically, it’s not a good idea to blindly use -9 for everything like it often is with gzip and bzip2.
On the same hardware, the decompression speed is approximately a constant number of bytes of compressed data per second. In other words, the better the compression, the faster the decompression will usually be. This also means that the amount of uncompressed output produced per second can vary a lot. The following table summarises the features of the presets:
Column descriptions: • DictSize is the LZMA2 dictionary size. It is waste of memory to use a dictionary bigger than the size of the uncompressed file. This is why it is good to avoid using the presets -7 … -9 when there’s no real need for them. At -6 and lower, the amount of memory wasted is usually low enough to not matter. • CompCPU is a simplified representation of the LZMA2 settings that affect compression speed. The dictionary size affects speed too, so while CompCPU is the same for levels -6 … -9, higher levels still tend to be a little slower. To get even slower and thus possibly better compression, see –extreme. • CompMem contains the compressor memory requirements in the single-threaded mode. It may vary slightly between xz versions. Memory requirements of some of the future multithreaded modes may be dramatically higher than that of the single-threaded mode. • DecMem contains the decompressor memory requirements. That is, the compression settings determine the memory requirements of the decompressor. The exact decompressor memory usage is slightly more than the LZMA2 dictionary size, but the values in the table have been rounded up to the next full MiB. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| -e, –extreme | Use a slower variant of the selected compression preset level (-0 … -9) to hopefully get a little bit better compression ratio, but with bad luck this can also make it worse. Decompressor memory usage is not affected, but compressor memory usage increases a little at preset levels -0 … -3. Since there are two presets with dictionary sizes 4 MiB and 8 MiB, the presets -3e and -5e use slightly faster settings (lower CompCPU) than -4e and -6e, respectively. That way no two presets are identical.
For example, there are a total of four presets that use 8 MiB dictionary, whose order from the fastest to the slowest is -5, -6, -5e, and -6e. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| –fast, –best | These are somewhat misleading aliases for -0 and -9, respectively. These are provided only for backward compatibility with LZMA Utils. Avoid using these options. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| –block-size=size | When compressing to the .xz format, split the input data into blocks of size bytes. The blocks are compressed independently from each other. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| –memlimit-compress=limit | Set a memory usage limit for compression. If this option is specified multiple times, the last one takes effect. If the compression settings exceed the limit, xz will adjust the settings downwards so that the limit is no longer exceeded and display a notice that automatic adjustment was done. Such adjustments are not made when compressing with –format=raw or if –no-adjust is specified. In those cases, an error is displayed and xz will exit with exit status 1. The limit can be specified in multiple ways: • The limit can be an absolute value in bytes. Using an integer suffix like MiB can be useful. Example: –memlimit-compress=80MiB • The limit can be specified as a percentage of total physical memory (RAM). This can be useful especially when setting the XZ_DEFAULTS environment variable in a shell initialization script that is shared between different computers. That way the limit is automatically bigger on systems with more memory. Example: –memlimit-compress=70% • The limit can be reset back to its default value by setting it to 0, which is currently equivalent to setting the limit to max (no memory usage limit). Once multithreading support is implemented, there may be a difference between 0 and max for the multithreaded case, so it is recommended to use 0 instead of max until the details are decided. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| –memlimit-decompress = limit | Defina um limite de uso de memória para descompactação. Isso também afeta o modo –list . Se a operação não for possível sem exceder o limite, xz exibirá um erro e a descompactação do arquivo falhará. Veja –memlimit-compress = limit para formas possíveis de especificar o limite. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| -M limite , –memlimit = limite , –memory = limite | Esta opção é equivalente a especificar –memlimit-compress = limit –memlimit-decompress = limit . | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| – sem ajuste | Exiba um erro e saia se as configurações de compactação excederem o limite de uso de memória. O padrão é ajustar as configurações para baixo, para que o limite de uso da memória não seja excedido. O ajuste automático é sempre desativado ao criar fluxos brutos ( –format = bruto ). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| -T threads , –threads = threads | Especifique o número de threads de trabalho a serem usados. O número real de threads pode ser menor que threads, se o uso de mais threads exceder o limite de uso de memória. A compactação e descompactação multithread ainda não foram implementadas, portanto, esta opção não tem efeito no momento. |
Correntes de filtro de compressor personalizadas
Uma cadeia de filtros personalizada permite especificar as configurações de compactação em detalhes, em vez de depender das configurações associadas aos níveis predefinidos. Quando uma cadeia de filtros personalizada é especificada, as opções de nível de predefinição de compactação ( -0 … -9 e –extreme ) são ignoradas silenciosamente.
Uma cadeia de filtros é comparável à tubulação na linha de comando. Ao compactar, a entrada não compactada vai para o primeiro filtro, cuja saída vai para o próximo filtro (se houver). A saída do último filtro é gravada no arquivo compactado. O número máximo de filtros na cadeia é quatro, mas geralmente uma cadeia de filtros possui apenas um ou dois filtros.
Muitos filtros têm limitações sobre onde eles podem estar na cadeia de filtros: alguns filtros podem funcionar apenas como o último filtro da cadeia, outros apenas como um filtro não-último e alguns funcionam em qualquer posição na cadeia. Dependendo do filtro, essa limitação é inerente ao design do filtro ou existe para evitar problemas de segurança.
Uma cadeia de filtros personalizada é especificada usando uma ou mais opções de filtro na ordem em que são desejadas na cadeia de filtros. Ou seja, a ordem das opções de filtro é significativa! Ao decodificar fluxos brutos ( –format = bruto ), a cadeia do filtro é especificada na mesma ordem em que foi especificada ao compactar.
Os filtros aceitam opções específicas de filtro como uma lista separada por vírgula. Vírgulas extras nas opções são ignoradas. Cada opção tem um valor padrão, portanto, você precisa especificar apenas aqueles que deseja alterar.
| –lzma1 [ = opções ], –lzma2 [ = opções ] | Adicione o filtro LZMA1 ou LZMA2 à cadeia de filtros. Esses filtros podem ser usados apenas como o último filtro na cadeia. O LZMA1 é um filtro herdado, suportado quase exclusivamente devido ao formato de arquivo .lzma herdado , que suporta apenas o LZMA1. LZMA2 é uma versão atualizada do LZMA1 para corrigir alguns problemas práticos do LZMA1. O formato .xz usa LZMA2 e não oferece suporte a LZMA1. A velocidade de compressão e as proporções de LZMA1 e LZMA2 são praticamente as mesmas. LZMA1 e LZMA2 compartilham o mesmo conjunto de opções:
Ao decodificar fluxos brutos ( –format = bruto ), o LZMA2 precisa apenas do tamanho do dicionário. O LZMA1 também precisa de lc , lp e pb . | ||||||||||||||||||||||||||||
| –x86 [ = opções ] –powerpc [ = opções ] –ia64 [ = opções ] –arm [ = opções ] –armthumb [ = opções ] –sparc [ = opções ] | Add a branch/call/jump (BCJ) filter to the filter chain. These filters can be used only as a non-last filter in the filter chain. A BCJ filter converts relative addresses in the machine code to their absolute counterparts. This doesn’t change the size of the data, but it increases redundancy, which can help LZMA2 to produce 0-15 % smaller .xz file. The BCJ filters are always reversible, so using a BCJ filter for wrong type of data doesn’t cause any data loss, although it may make the compression ratio slightly worse. It is fine to apply a BCJ filter on a whole executable; there’s no need to apply it only on the executable section. Applying a BCJ filter on an archive that contains both executable and non-executable files may or may not give good results, so it generally isn’t good to blindly apply a BCJ filter when compressing binary packages for distribution. These BCJ filters are very fast and use insignificant amount of memory. If a BCJ filter improves compression ratio of a file, it can improve decompression speed at the same time. This is because, on the same hardware, the decompression speed of LZMA2 is roughly a fixed number of bytes of compressed data per second. These BCJ filters have known problems related to the compression ratio: • Some types of files containing executable code (e.g., object files, static libraries, and Linux kernel modules) have the addresses in the instructions filled with filler values. These BCJ filters will still do the address conversion, which will make the compression worse with these files. • Applying a BCJ filter on an archive containing multiple similar executables can make the compression ratio worse than not using a BCJ filter. This is because the BCJ filter doesn’t detect the boundaries of the executable files, and doesn’t reset the address conversion counter for each executable. Both of the above problems will be fixed in the future in a new filter. The old BCJ filters will still be useful in embedded systems, because the decoder of the new filter will be bigger and use more memory. Different instruction sets have different alignment:
Since the BCJ-filtered data is usually compressed with LZMA2, the compression ratio may be improved slightly if the LZMA2 options are set to match the alignment of the selected BCJ filter. For example, with the IA-64 filter, it’s good to set pb=4 with LZMA2 (2^4=16). The x86 filter is an exception; it’s usually good to stick to LZMA2’s default four-byte alignment when compressing x86 executables. All BCJ filters support the same options:
| ||||||||||||||||||||||||||||
| –delta[=options] | Add the Delta filter to the filter chain. The Delta filter can be only used as a non-last filter in the filter chain. Currently only simple byte-wise delta calculation is supported. It can be useful when compressing e.g., uncompressed bitmap images or uncompressed PCM audio. However, special purpose algorithms may give significantly better results than Delta + LZMA2. This is true especially with audio, which compresses faster and better e.g., with flac. Supported options:
|
Other options
| -q , –quiet | Suprimir avisos e avisos. Especifique isso duas vezes para suprimir erros também. Esta opção não tem efeito no status de saída. Ou seja, mesmo que um aviso tenha sido suprimido, o status de saída para indicar um aviso ainda é usado. |
| -v , –verbose | Seja detalhado . Se um erro padrão estiver conectado a um terminal, xz exibirá um indicador de progresso. A especificação de –verbose duas vezes fornece uma saída ainda mais detalhada. O indicador de progresso mostra as seguintes informações: • A porcentagem de conclusão é mostrada se o tamanho do arquivo de entrada for conhecido. Ou seja, a porcentagem não pode ser mostrada nos tubos. • Quantidade de dados compactados produzidos (compactando) ou consumidos (descompactando). • Quantidade de dados não compactados consumidos (compactados) ou produzidos (descompactados). • Taxa de compactação, calculada dividindo a quantidade de dados compactados processados até o momento pela quantidade de dados não compactados processados até o momento. • Velocidade de compressão ou descompressão. Isso é medido como a quantidade de dados não compactados consumidos (compactação) ou produzidos (descompactação) por segundo. É mostrado após alguns segundos desde que o xz começou a processar o arquivo. • Tempo decorrido no formato M: SS ou H: MM: SS . • O tempo restante estimado é mostrado apenas quando o tamanho do arquivo de entrada é conhecido e já se passaram alguns segundos desde que o xz começou a processar o arquivo. A hora é mostrada em um formato menos preciso, que nunca possui dois pontos, por exemplo, 2 min 30 s. Quando o erro padrão não é um terminal, –verbose fará xzimprima o nome do arquivo, tamanho compactado, tamanho não compactado, taxa de compactação e, possivelmente, também a velocidade e o tempo decorrido em uma única linha para erro padrão após compactar ou descompactar o arquivo. A velocidade e o tempo decorrido são incluídos apenas quando a operação leva pelo menos alguns segundos. Se a operação não foi concluída, por exemplo, devido à interrupção do usuário, também a porcentagem de conclusão será impressa se o tamanho do arquivo de entrada for conhecido. |
| -Q , –no-warn | Não defina o status de saída como 2, mesmo que uma condição que valha um aviso tenha sido detectada. Esta opção não afeta o nível de verbosidade, portanto, –quiet e –no-warn devem ser usados para não exibir avisos e não alterar o status de saída. |
| –robô | Imprima mensagens em um formato analisável por máquina. Isso visa facilitar a criação de front-end que desejam usar xz em vez de liblzma, o que pode ser o caso de vários scripts. A saída com esta opção ativada deve ser estável nas versões xz . Veja a seção MODO ROBÔ para detalhes. |
| –info-memory | Exiba, em formato legível por humanos, a quantidade de memória física (RAM) xz que o sistema possui e os limites de uso de memória para compactação e descompactação, e saia com êxito. |
| -h , –help | Exiba uma mensagem de ajuda descrevendo as opções mais usadas e saia com sucesso. |
| -H , –long-help | Exiba uma mensagem de ajuda descrevendo todos os recursos do xz e saia com sucesso. |
| -V , –version | Exibir o número da versão xz e liblzma em formato legível. Para obter a saída de máquina-parsable, especifique –robot antes –version . |
Modo robô
O modo robô é ativado com a opção –robot . Torna a saída do xz mais fácil de analisar por outros programas. Atualmente –robot é suportado apenas junto com –version , –info-memory e –list . Ele será suportado para compactação e descompactação normal no futuro.
Modo robô: versão
xz –robot –version imprimirá o número da versão de xz e liblzma no seguinte formato:
XZ_VERSION = XYYYZZZS LIBLZMA_VERSION = XYYYZZZS
Aqui está o que o número da versão significa, parte por parte:
| X | Versão principal. |
| AAAA | Versão secundária. Números pares são estáveis. Os números ímpares são versões alfa ou beta. |
| ZZZ | Nível de patch para versões estáveis ou um contador para versões de desenvolvimento. |
| S | Estabilidade. 0 é alfa, 1 é beta e 2 é estável. S deve ser sempre 2 quando AA for igual. |
| XYYYZZZS | São iguais nas duas linhas se xz e liblzma forem da mesma versão do XZ Utils. |
Exemplos: 4.999.9beta é 49990091 e 5.0.0 é 50000002 .
Modo de robô: informações de limite de memória
xz –robot –info-memory imprime uma única linha com três colunas separadas por tabulação:
- Quantidade total de memória física (RAM) em bytes
- Limite de uso de memória para compactação em bytes. Um valor especial de zero indica a configuração padrão, que para o modo de thread único é igual a sem limite.
- Limite de uso de memória para descompactação em bytes. Um valor especial de zero indica a configuração padrão, que para o modo de thread único é igual a sem limite.
No futuro, a saída do xz –robot –info-memory pode ter mais colunas, mas nunca mais do que uma única linha.
Modo de robô: modo de lista
xz –robot –list usa saída separada por tabulação. A primeira coluna de cada linha possui uma sequência que indica o tipo de informação encontrada nessa linha:
| nome | Essa é sempre a primeira linha ao iniciar a lista de um arquivo. A segunda coluna na linha é o nome do arquivo. |
| Arquivo | Esta linha contém informações gerais sobre o arquivo .xz . Esta linha é sempre impressa após a linha de nome. |
| corrente | Esse tipo de linha é usado apenas quando –verbose foi especificado. Existem tantas linhas de fluxo quanto o arquivo .xz . |
| quadra | This line type is used only when –verbose was specified. There are as many block lines as there are blocks in the .xz file. The block lines are shown after all the stream lines; different line types are not interleaved. |
| summary | This line type is used only when –verbose was specified twice. This line is printed after all block lines. Like the file line, the summary line contains overall information about the .xz file. |
| totals | This line is always the very last line of the list output. It shows the total counts and sizes. |
The columns of the file lines are:
- Number of streams in the file.
- Total number of blocks in the stream(s.
- Compressed size of the file.
- Uncompressed size of the file.
- Compression ratio, for example 0.123. If ratio is over 9.999, three dashes (—) are displayed instead of the ratio.
- Comma-separated list of integrity check names. The following strings are used for the known check types: None, CRC32, CRC64, and SHA-256. For unknown check types, Unknown-N is used, where N is the Check ID as a decimal number (one or two digits).
- Total size of stream padding in the file.
The columns of the stream lines are:
- Stream number (the first stream is 1).
- Number of blocks in the stream.
- Compressed start offset.
- Uncompressed start offset.
- Compressed size (does not include stream padding).
- Uncompressed size.
- Compression ratio.
- Name of the integrity check.
- Size of stream padding.
The columns of the block lines are:
- Number of the stream containing this block.
- Block number relative to the beginning of the stream (the first block is 1).
- Block number relative to the beginning of the file.
- Compressed start offset relative to the beginning of the file.
- Uncompressed start offset relative to the beginning of the file.
- Total compressed size of the block (includes headers).
- Uncompressed size.
- Compression ratio.
- Name of the integrity check.
If –verbose was specified twice, additional columns are included on the block lines. These are not displayed with a single –verbose, because getting this information requires many seeks and can thus be slow:
- Value of the integrity check in hexadecimal.
- Block header size.
- Block flags: c indicates that compressed size is present, and u indicates that uncompressed size is present. If the flag is not set, a dash (-) is shown instead to keep the string length fixed. New flags may be added to the end of the string in the future.
- Size of the actual compressed data in the block (this excludes the block header, block padding, and check fields).
- Amount of memory (in bytes) required to decompress this block with this xz version.
- Filter chain. Note that most of the options used at compression time cannot be known, because only the options that are needed for decompression are stored in the .xz headers.
The columns of the summary lines are:
- Amount of memory (in bytes) required to decompress this file with this xz version.
- yes or no indicating if all block headers have both compressed size and uncompressed size stored in them since xz 5.1.2alpha.
- Minimum xz version required to decompress the file.
The columns of the totals line:
- Number of streams.
- Number of blocks.
- Compressed size.
- Uncompressed size.
- Average compression ratio.
- Comma-separated list of integrity check names that were present in the files.
- Stream padding size.
- Number of files. This is here to keep the order of the earlier columns the same as on file lines.
If –verbose was specified twice, additional columns are included on the totals line:
- Maximum amount of memory (in bytes) required to decompress the files with this xz version.
- yes or no indicating if all block headers have both compressed size and uncompressed size stored in them.
- Minimum xz version required to decompress the file.
Exit status
| 0 | Everything was successful. |
| 1 | An error occurred. |
| 2 | Something worthy of a warning occurred, but no errors. |
Environment
xz parses space-separated lists of options from the environment variables XZ_DEFAULTS and XZ_OPT, in this order, before parsing the options from the command line. Note that only options are parsed from the environment variables; all non-options are silently ignored.
| XZ_DEFAULTS | User-specific or system-wide default options. Often this is set in a shell initialization script to enable xz‘s memory usage limiter by default. Excluding shell initialization scripts and similar special cases, scripts must never set or unset XZ_DEFAULTS. |
| XZ_OPT | This is for passing options to xz when it is not possible to set the options directly on the xz command line. This is the case e.g., when xz is run by a script or tool, e.g., GNU tar:XZ_OPT=-2v tar caf foo.tar.xz foo Os scripts podem usar XZ_OPT, por exemplo, para definir opções de compactação padrão específicas do script. Ainda é recomendável permitir que os usuários substituam XZ_OPT se isso for razoável, por exemplo, nos scripts sh, pode-se usar algo como isto: XZ_OPT = $ {XZ_OPT - "- 7e"}; exportar XZ_OPT |
Exemplos
xz foo
Compacte o arquivo foo em foo.xz usando o nível de compactação padrão ( -6 ) e remova foo se a compactação for bem-sucedida.
xz -dk bar.xz
Descomprimir bar.xz em bar e não remova bar.xz mesmo se descompressão é bem sucedida.
tar cf - baz | xz -4e> baz.tar.xz
Crie baz.tar.xz com a predefinição -4e ( -4 –extreme ), que é mais lenta que o padrão -6 , mas precisa de menos memória para compactação e descompactação (48 MiB e 5 MiB, respectivamente).
xz -dcf a.txt b.txt.xz c.txt d.txt.lzma> abcd.txt
Descompacte uma mistura de arquivos compactados e descompactados na saída padrão, usando um único comando.
Comandos relacionados
compactar – Comprime um arquivo ou arquivos.
gzip – Crie, modifique, liste o conteúdo e extraia arquivos dos arquivos zip do GNU.
zip – Um utilitário de compactação e arquivamento.